Predicting College Graduate Earnings
DrivenData | Machine Learning Competition
1st place win (RMSE: 2.9796)
Project Description
Regression analysis and prediction of college earnings N years following graduation over anonymized college graduate data provided by the U.S. Department of Education: College Scorecard.
Skills
Data Analysis, Data Cleaning, Regression, Feature Interactions & Selection, Ensemble Methods, Generalized Stacking, Written Communication
Tools
Python, Pandas, NumPy, Matplotlib, Jupyter, Seaborn, AdaBoost, Extra Trees and Random Forest, Gradient Boosted Decision Trees, Microsoft LightGBM, XGBoost
Motivation
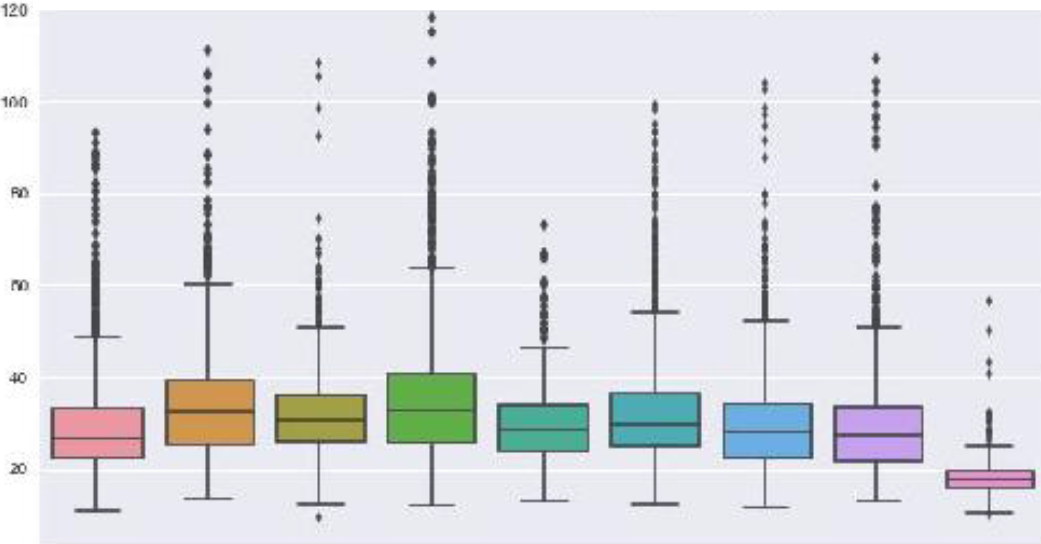
Potential earning-power is a motivating factor for many college students, but the critical educational institution characteristics that contribute most to financial success are not well advertised. In this machine learning competition hosted in 2017 by DrivenData, competitors were asked to evaluate 17,107 post-collegiate outcomes across 297 independent variables and construct a model that predicts 9,912 test samples. Competitors model performance was evaluated via the lowest root mean squared error.
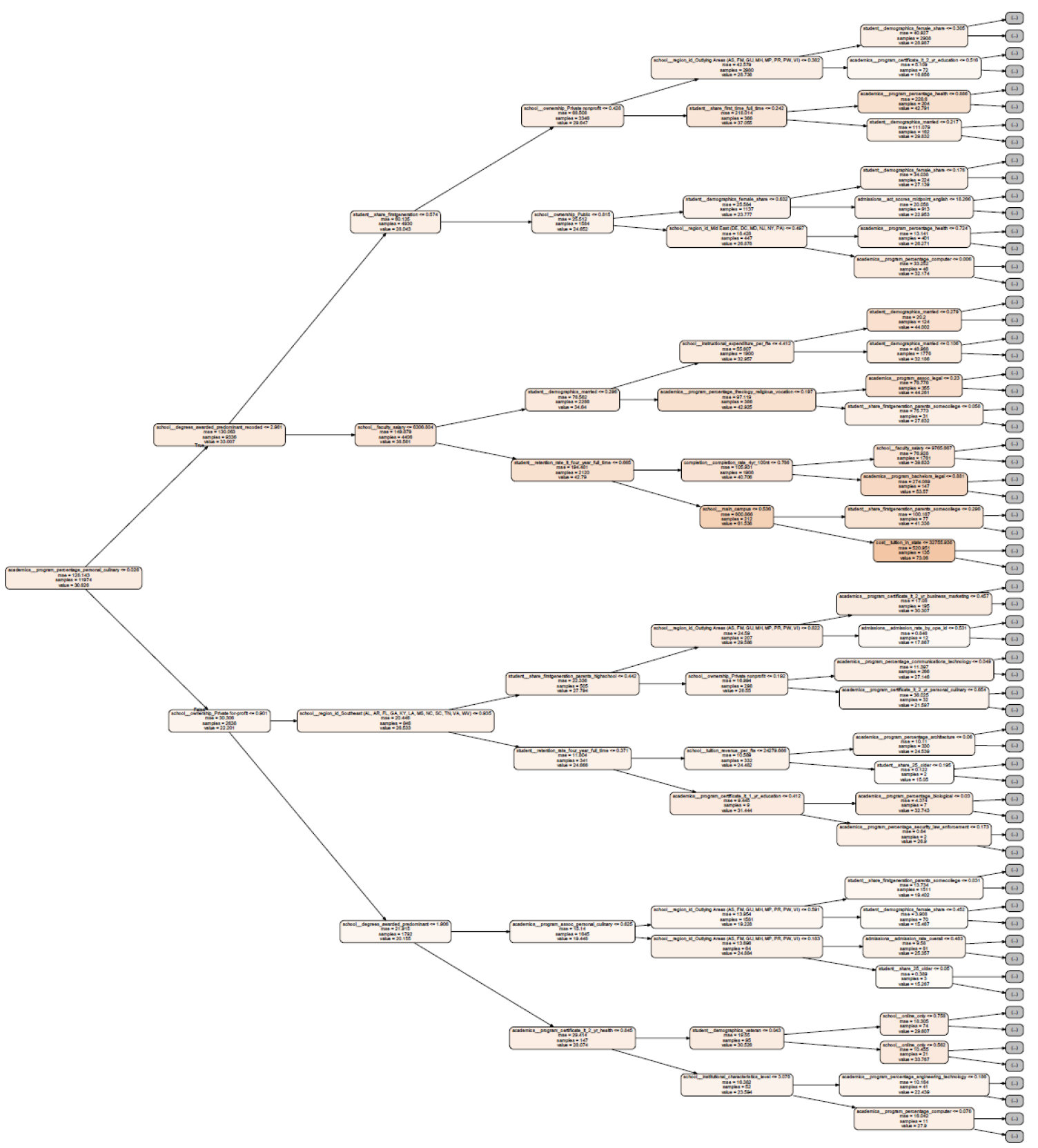
There were many interesting findings in the data; though school name and location were anonymized - it was fairly easy to identify the typical Ivy League schools through significantly higher tuition costs, high-rates of legacy parental attendance, and well above-average SAT scores. Though it was not surprising that these students often had the highest income outcomes post-graduation, the best positive indicator for high-tier income was the school status of 'public, nonprofit' and the presence of Ph.D. programs. Surprisingly, the best signal for low-tier earnings outcomes was the presence of a 2-or-4 year culinary program and a 'private, for-profit' status.
The greatest improvements to model performance were: (a) the use of generalized stacking of seven tree-based models (with a linear meta-model), (b) manual synthezation of quadratic feature interactions, (c) careful interpolation of missing data through a separate regressor, (d) clipping of outliers, (e) removal of duplicate observations in the training dataset, and (f) derivation of new features that captured ordinal rank of anonymized states and student demographics.
See the complete project in my GitHub repository.