Identifying Topics of World Bank Publications
DrivenData | Machine Learning Competition
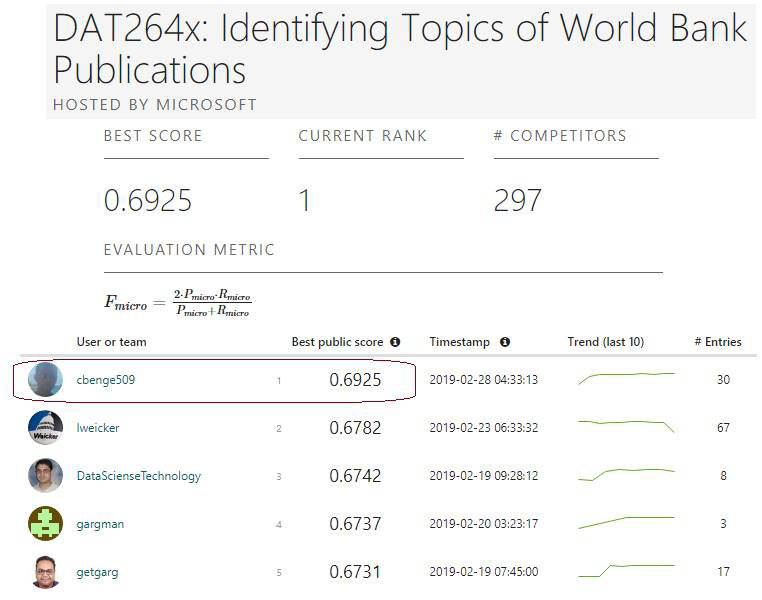
1st place (F1-micro: 0.6925)

Project Description
Multi-label, multi-class classification NLP machine learning competition; topic identification of World Bank publications.
Skills
Natural Language Processing, Classification, Multi-Label, Stemming, TF-IDF, LSTM / GRU, Neural Network (Dense), Over/Under Sampling, SMOTE, Word2Vec / Glove / Custom Word Embeddings, Adversarial Validation
Tools
Python, Pandas, NumPy, Keras, TensorFlow, Matplotlib, Seaborn, NLTK, Plotly, LightGBM
Motivation
The World Bank is an international financial institution that, in addition to providing loans and grants to governments, studies and publishes on the nuances of economic conditions and inequality. Many of their publications are classified into one or more categories, such as: Macroeconomics, Private Sector, Poverty Reduction, Law and Development, Technology, etc. For this challenge, competitors were provided with 18,660 training examples of publications in a raw format and asked to predict the label(s) for 18,738 test samples.
Adversarial validation was used to ensure that the distribution of test and train datasets were similiar enough to make reasonable inference from. A significant amount of clean-up was required to make use of the data for tokenization; many documents were missing spaces creating extremely large run-on-words - effort was made utilizing probabilistic distribution models to segment words. Class-imbalance was a significant problem in the train dataset; random oversampling produced better cross validation scores but overfit and generalized poorly. SMOTE was leveraged to better effect for this problem though some overfitting persisted.
Various modeling techniques were tried, including TF-IDF driven trees and dense neural networks on popular word embeddings (Glove/Word2Vec); however, a custom vocabulary performed best. Transformer models were evaluated but had marginal impact on results and were thus abandoned for simpler models. In the end, the key insight that advantaged me over the other competitors was a shockingly simple insight missed by all others: The organizers had slipped ~4k observations from train into the test dataset. It's not clear if this was intentional or inadvertent - but by holding those observations out from prediction and simply passing the labels in post-prediction I was able to move from #2 to #1 spot in the final week.
See the complete project in my GitHub repository.